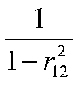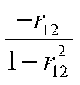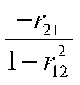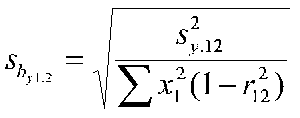
Collinearity
Questions: What is collinearity? Why is it a problem? How do I know if I've got it? What can I do about it?
Materials
When IVs are correlated, there are problems in estimating regression coefficients. Collinearity means that within the set of IVs, some of the IVs are (nearly) totally predicted by the other IVs. The variables thus affected have b and b weights that are not well estimated (the problem of the "bouncing betas"). Minor fluctuations in the sample (measurement errors, sampling error) will have a major impact on the weights.
Diagnostics
Variance Inflation Factor (VIF)
The standard error of the b weight with 2 IVs
This is the square root of the mean square residual over the sum of squares X1 times 1 minus the squared correlation between IVs.
The sampling variance of the b weight with 2 IVs:
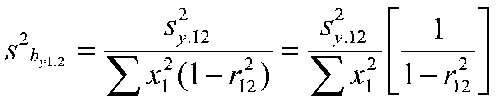
Notice the term on the far right.
The standard error of the b weight with multiple IVs:
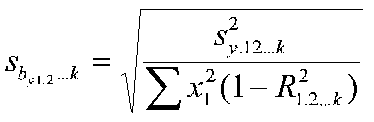
The term on the bottom right is the squared correlation where IV 1 is considered as a DV and all the other IVs are treated as IVs. The R-square term tells us how predcictable our IV is from the set of other IVs. It tells us about the linear dependence of one IV on all the other IVs.
The VIF for variable b1:
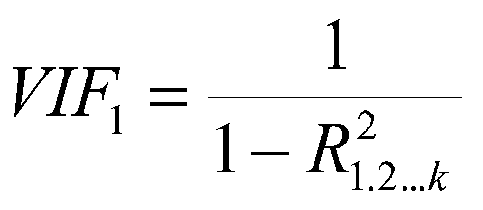
The VIF for variable i:

Big values of VIF are trouble. Some say look for values of 10 or larger, but there is no certain number that spells death. The VIF is also equal to the diagonal element of
R-1, the inverse of the correlation matrix of IVs. Recall that
b
=R-1r, so we need to find R-1 to find the beta weights.
This is easiest to see with a 2x2 matrix:
|
R = |
1 |
r12 |
|
|
r21 |
1 |
The determinant of R is |R| = (1)(1)-(r12)(r21) = 1 - r212. To find the inverse, we have to interchange main diagonal elements, reverse the sign of the off-diagonal elements, and divide each element by the determinant, like this:
|
R-1 = |
|
|
|
|
|
|
As you can see, when r212 is large, VIF will be large.
When R is of order greater than 2 x 2, the main diagonal elements of R are 1/ R2i, so we have the multiple correlation of the X with the other IVs instead of the simple correlation.
Tolerance
Tolerance = 1 - R2i = 1/VIFi
Small values of tolerance (close to zero) are trouble. Some computer programs will complain to you about tolerance. Do not interpret such complaints as computerized comments on silicon diversity; rather look to problems in collinearity.
Condition Indices
Most multivariate statistical approaches (factor analysis, MANOVA, cannonical correlation, etc.) involve decomposing a correlation matrix into linear combinations of variables. The linear combinations are chosen so that the first combination has the largest possible variance (subject to some restrictions we won't discuss), the second combination has the next largest variance, subject to being uncorrelated with the first, the third has the largest possible variance, subject to being uncorrelated with the first and second, and so forth. The variance of each of these linear combinations is called an eigenvalue. You will learn about the kinds of decompositions and their uses in a course on multivariate statistics. We will only be using the eigenvalue for diagnosing collinearity in multiple regression.
SAS will produce a table for you that looks kind of like this (if you have 3 IVs): (Pedhazur, p. 303):
|
Number |
Eigenval |
Condition |
Variance Proportions |
|||
|
|
|
Index |
Constant |
X1 |
X2 |
X3 |
|
1 |
3.771 |
1.00 |
.004 |
.006 |
.006 |
.008 |
|
2 |
.106 |
5.969 |
.003 |
.029 |
.268 |
.774 |
|
3 |
.079 |
6.90 |
.000 |
.749 |
.397 |
.066 |
|
4 |
.039 |
9.946 |
.993 |
.215 |
.329 |
.152 |
Number stands for linear combination of X variables. Eigenval(ue) stands for the variance of that combination. The condition index is a simple function of the eigenvalues, namely,
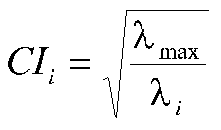
where l is the conventional symbol for an eigenvalue.
To use the table, you first look at the variance proportions. For X1, for example, most of the variance (about 75 percent) is associated with Number 3, which has an eigenvalue of .079 and a condition index of 6.90. Most of the rest of X1 is associated with Number 4. Variable X2 is associated with 3 different numbers (2, 3, & 4), and X3 is mostly associated with Number 2. Look for variance proportions about .50 and larger. Collinearity is spotted by finding 2 or more variables that have large proportions of variance (.50 or more) that correspond to large condition indices. A rule of thumb is to label as large those condition indices in the range of 30 or larger. There is no evident problem with collinearity in the above example. There is thought be a problem indicated in the example below (Pedhazur, p. 303):
|
Number |
Eigenval |
Condition |
Variance Proportions |
|||
|
|
|
Index |
Constant |
X1 |
X2 |
X3 |
|
1 |
3.819 |
1.00 |
.004 |
.006 |
.002 |
.002 |
|
2 |
.117 |
5.707 |
.043 |
.384 |
.041 |
.087 |
|
3 |
.047 |
9.025 |
.876 |
.608 |
.001 |
.042 |
|
4 |
.017 |
15.128 |
.077 |
.002 |
.967 |
.868 |
The last condition index (15.128) is highly associated with X2 and X3. The b weights for X2 and X3 are probably not well estimated.
How to Deal with Collinearity
As you may have noticed, there are rules of thumb in deciding whether collinearity is a problem. People like to conclude that collinearity is not a problem. However, you should at least check to see if it seems to be a problem with your data. If it is, then you have some choices: